Some people have trouble envisaging what a database is. That’s not surprising given that most databases consist of a number of component parts. But if you think of word processors as… well… processors of words, and spreadsheets as number processors, then you can think of databases as data processors. Feed a database data in any sort of guise – as numbers, text, dates, images, Web links – and it will digest all that data and turn it into usable information.
Another way to help distinguish a database from a spreadsheet (and there are, in fact, many time when you could just as easily use one as the other) is in terms of what sort of information you can get out of it. A spreadsheet lets you posit questions such as “Can I afford the monthly payments on that $290,000 house?” or “What’s the average daily rainfall for the first six months of this year?” or “If we increase our sales of doohickies by four percent while reducing the price by a dollar a piece, how will it affect profits?” Spreadsheets excel at answering financial, numerical and statistical questions such as these.
You can ask quite different questions of a database. For example, “What are the phone numbers and addresses of the five nearest post offices to the school?”, “Do we have any books in our library that deal with irradiated food? If so, on which shelves are they located?”, “Show me the personnel records and sales figures of our five best-performing sales people for the current quarter, but don’t bother me with their address details.”
As you can see, databases deal with a broader scope of information than spreadsheets. The chief job of a database is to provide answers to questions. In fact, one of the major components of most databases is a query tool – a special component which lets you formulate questions (‘queries’) that will illicit useful answers from all your stored data.
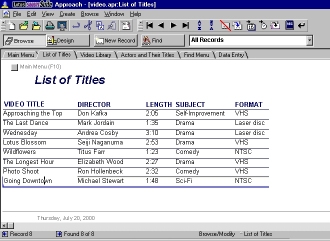
A multi-file database.
Database building blocks
Of course, before you can ask any questions you need to build a structure to hold your data, and you need a way of adding data to that structure. So, most databases come with multiple components: a database designer for structuring the data; a forms designer for building data entry forms; a query engine for asking questions of that data; and a report builder for printing the results of a query.
It doesn’t stop there. Many databases also provide a way to tie together and automate procedures so you can build entire applications that offer users push-button ease (well, that’s the goal, anyway). Some database programs, such as Microsoft Access, include fully fledged programming languages for building applications. Others, such as FileMaker Pro and Lotus Approach, have beefed up macros or scripting languages that are easier to use but not quite as flexible as a programming language.

A menu-driven database application.
Think ahead
The most important thing to do when you start creating a database is to think ahead. Before you even switch on the computer, think about the type of information you have to work with and the types of questions you’ll want your database to answer.
For instance, say you want to create a membership list for your organisation. You’ll want to store the name, address and phone number of each member, plus other details such as the year they first joined, type of membership, whether they’re up to date with their membership dues, and so on. That gives us the following structure:
-
Name
-
Address
-
Phone
-
Year Joined
-
Membership Type
-
Dues owed
That seems clear enough. But what happens if you decide to print a membership list sorted alphabetically by family name – a very common requirement? There’s no easy way to do it, so it makes sense to break the Name into its component parts: Given Name, Middle Initial, Family Name.
The same goes for the address. It, too, can be usefully broken down into Street Address, Suburb, State and Postal Code. That will enable you to print off envelopes sorted by postcode/zip and help you qualify for pre-sorted, bulk mail rates.
Payoffs for planning
As you can see, even in a seemingly simple database such as this, a little forethought can make a huge difference. Imagine that
you’d used the original database structure above, entered the details for all 1700 of your members, and only then realised you wanted an alphabetical list.
You’d have to add the new fields and then either re-enter all the affected data or use some advanced techniques
– which, as a beginner, you’re unlikely to know – to reorganise the existing data.
So before you dive in to creating your first database, get out the old pencil and paper and do some hard thinking about what you want to achieve.
While you’re doing that, I’ll conclude the opener to this series with a rundown on database terminology. In coming tutorials, you’ll have a chance to build some databases from scratch, starting with simple, flat-file tables and working up to powerful relational databases. As you can tell from that last sentence, you’ll probably need the database dictionary below, so keep it handy. If you want a more thorough grounding in database terminology, you can always check out the Database Dictionary.
Database dialect
Here’s a quick guide to some of the more common database terms.
database: A collection of related information stored in a structured format. Database is often used interchangeably with the term table (Lotus Approach, for instance, uses the term database instead of table). Technically, they’re different: a table is a single store of related information; a database can consist of one or more tables of information that are related in some way. For instance, you could track all the information about the students in a school in a students table. If you then created separate tables containing details about teachers, classes and classrooms, you could combine all four tables into a timetabling database. Such a multi-table database is called a relational database.
data entry: The process of getting information into a database, usually done by people typing it in by way of data-entry forms designed to simplify the process.
dbms: Database management system. A program which lets you manage information in databases. Lotus Approach, Microsoft Access and FileMaker Pro, for example, are all DBMSs, although the term is often shortened to ‘database’. So, the same term is used to apply to the program you use to organise your data and the actual data structure you create with that program.
field: Fields describe a single aspect of each member of a table. A student record, for instance, might contain a last name field, a first name field, a date of birth field and so on. All records have exactly the same structure, so they contain the same fields. The values in each field vary from record to record, of course.
flat file: A database that consists of a single table. Lightweight database programs such as the database component in Microsoft Works are sometimes called ‘flat-file managers’ (or list managers) because they can only handle single-table databases. More powerful programs, such as Access, FileMaker Pro and Approach, can handle multi-table databases, and are called relational database managers, or RDBMSs.
index: A summary table which lets you quickly locate a particular record or group of records in a table. Think of how you use an index to a book: as a quick jumping off point to finding full information about a subject. A database index works in a similar way. You can create an index on any field in a table. Say, for example, you have a customer table which contains customer numbers, names, addresses and other details. You can make indexes based on any information, such as the customers’ customer number, last name + first name (a composite index based on more than one field), or postal code. Then, when you’re searching for a particular customer or group of customers, you can use the index to speed up the search.
key field: You can sort and quickly retrieve information from a database by choosing one or more fields to act as keys. For instance, in a students table you could use a combination of the last name and first name fields as a key field. The database program will create an index containing just the key field contents. Using the index, you can quickly find any record by typing in the student’s name. The database will locate the correct entry in the index and then display the full record.
primary key: A field that uniquely identifies a record in a table. In a students table, a key built from last name + first name might not give you a unique identifier (two or more Jane Does in the school, for example). To uniquely identify each student, you might add a special Student ID field to be used as the primary key.
record: A record contains all the information about a single ‘member’ of a table. In our students table, each student’s details (name, date of birth, contact details, and so on) will be contained in its own record.
relational database: A database consisting of more than one table. In a multi-table database, you not only need to define the structure of each table, you also need to define the relationships between each table in order to link those tables correctly.
table: A single store of related information. A table consists of records, and each record is made up of a number of fields. You can think of the phone book as a table: It contains a record for each telephone subscriber, and each subscriber’s details are contained in three fields – name, address and telephone.
| top | home | beginners menu |